Introducción
Estás trabajando en una empresa y se te solicita un reporte con información compleja para que los directivos tomen ciertas decisiones…
¿Qué conocimientos de bases de datos requieres para elaborar los reportes?
El manejo de grandes volúmenes de información almacenada en bases de datos implica la inminente necesidad de tener un dominio avanzado del lenguaje SQL, lo cual te facilitará realizar consultas complejas que respondan a preguntas específicas para la toma de decisiones.
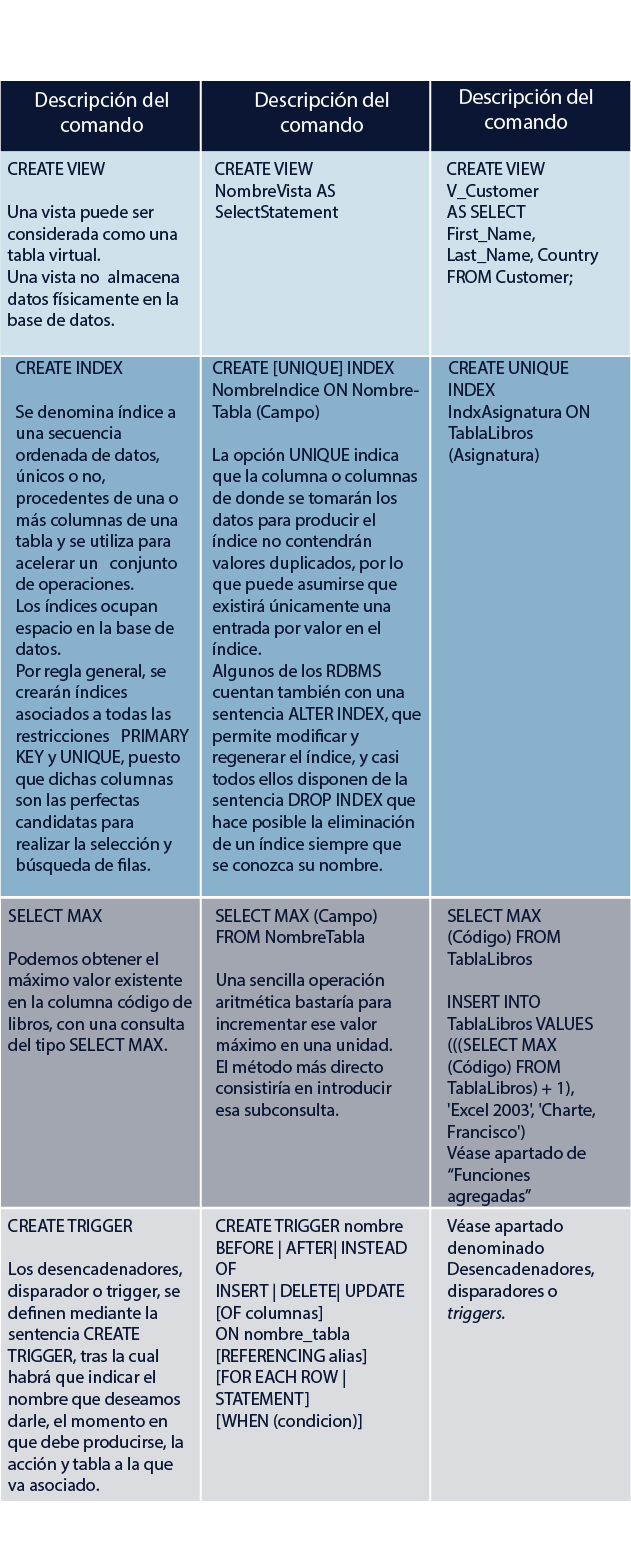
En este tema se identificarán los comandos asociados a los lenguajes DDL, DML y DCL, así como aspectos, notas y sintaxis relacionadas con los conceptos vistas, índices, secuencias en subconsultas y triggers.
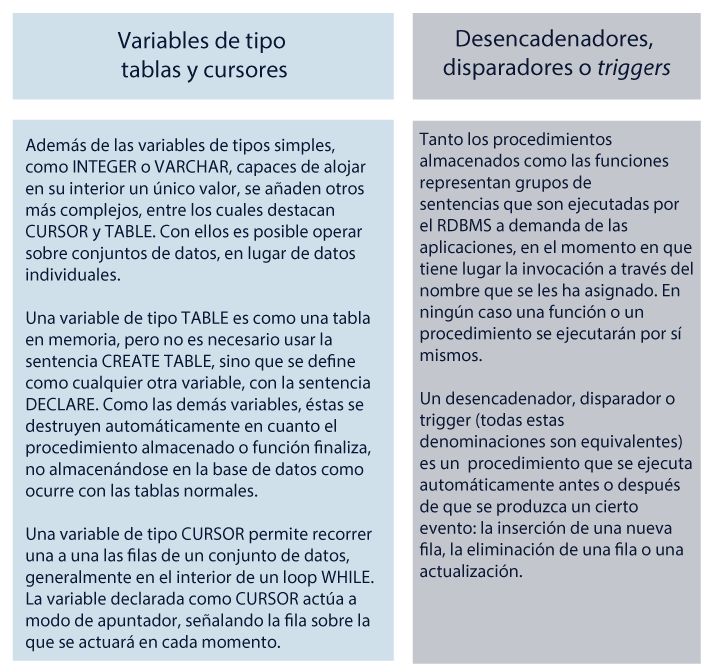
Por último, se abordarán los conceptos de variables de tipo tablas y cursores, triggers, procesamiento de transacciones, producto cartesiano; consultas inner join, outer join, full outer join, self join; así como adición de campos calculados, cálculos numéricos, operadores lógicos y relacionales, uso de paréntesis, agrupamiento y funciones de agregación.

Diseño de bases de datos