Introducción
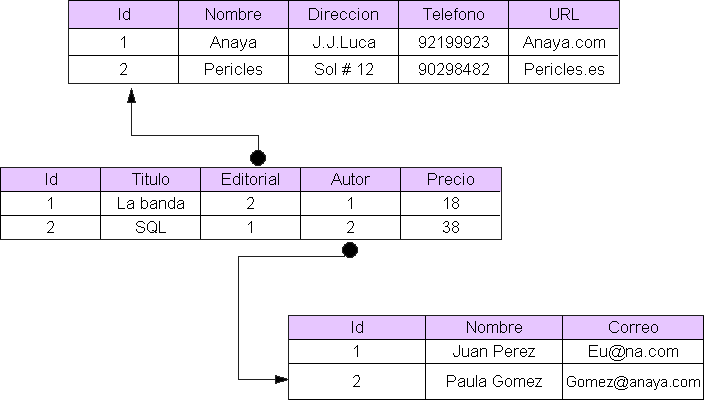
Un activo muy valioso para las organizaciones es la información, la cual debe ser completa y consistente. Para lograrlo, las organizaciones deben contar con una serie de restricciones de integridad referencial en el diseño de la base de datos.
¿Conoces dichas restricciones?
¿Cuál es la manera en que las entidades y atributos de la información deben comportarse?
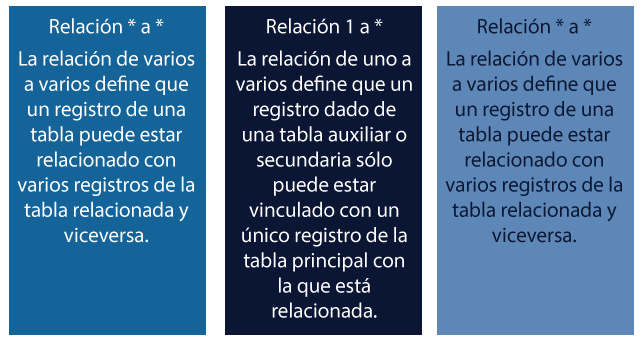
En este tema se desarrollarán los aspectos más importantes para añadir consistencia a los diseños de bases de datos bajo el modelo relacional como son las reglas de integridad, restricciones de integridad y cardinalidad.